
28年AGI撞上数据墙,以后全靠测试时计算?CMU详解优化原理
28年AGI撞上数据墙,以后全靠测试时计算?CMU详解优化原理2028年,预计高质量数据将要耗尽,数据Scaling走向尽头。2025年,测试时计算将开始成为主导AI通向通用人工智能(AGI)的新一代Scaling Law。近日,CMU机器学习系博客发表新的技术文章,从元强化学习(meta RL)角度,详细解释了如何优化LLM测试时计算。
来自主题: AI技术研报
7836 点击 2025-01-27 14:03
 搜索
搜索
2028年,预计高质量数据将要耗尽,数据Scaling走向尽头。2025年,测试时计算将开始成为主导AI通向通用人工智能(AGI)的新一代Scaling Law。近日,CMU机器学习系博客发表新的技术文章,从元强化学习(meta RL)角度,详细解释了如何优化LLM测试时计算。

OpenAI的新Scaling Law,含金量又提高了。

对 LLM 来说,Pre-training 的时代已经基本结束了。视频模型的 Scaling Law,瓶颈还很早。具身智能:完全具备人类泛化能力的机器人,在我们这代可能无法实现

下一代 AI 的发展,似乎遇到了难以逾越的瓶颈。去年 12 月,OpenAI 在 ChatGPT 两周年期间连续发布了 12 天,我们期待的新一代大模型 GPT-5 却从头到尾没有踪影。

我亲眼见证了数据量的爆炸式增长以及行业的巨额投入。当时就很明显,AI是推动这些数据增长背后的关键动力。那是一个非常有趣的时刻——Meta正在完成“移动优先”的过渡,开始迈向“AI 优先”。
近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。
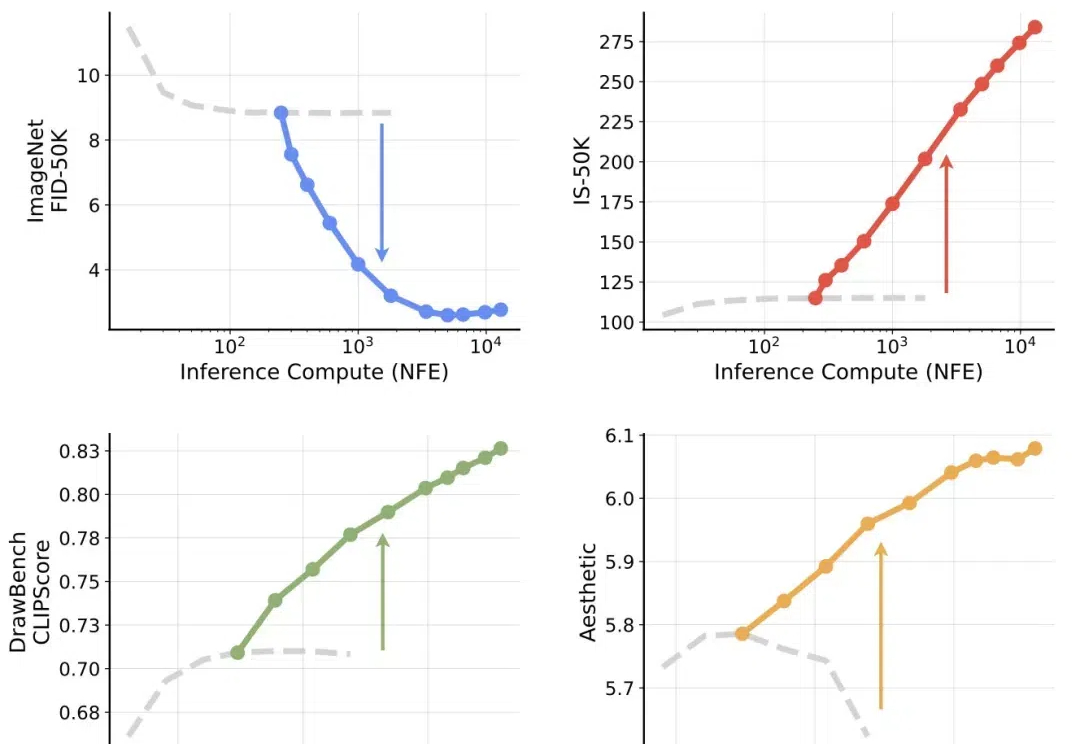
划时代的突破来了!来自NYU、MIT和谷歌的顶尖研究团队联手,为扩散模型开辟了一个全新的方向——测试时计算Scaling Law。其中,谢赛宁高徒为共同一作。

马斯克建超算速度,被中国这家公司用120天复刻了。119个集装箱,像搭积木一样拼出一座算力工厂。这不是科幻电影,而是浪潮信息交付的惊艳答卷。一个全新的AI时代,正在这里拉开序幕。
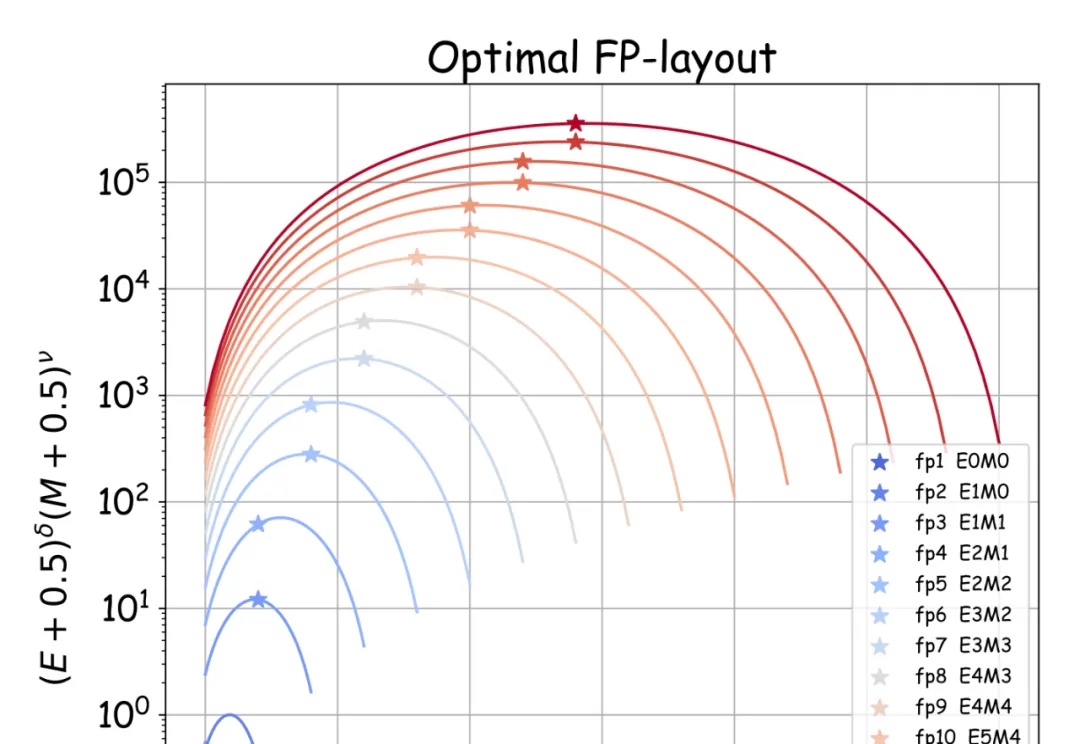
大模型低精度训练和推理是大模型领域中的重要研究方向,旨在通过降低模型精度来减少计算和存储成本,同时保持模型的性能。因为在大模型研发成本降低上的巨大价值而受到行业广泛关注 。
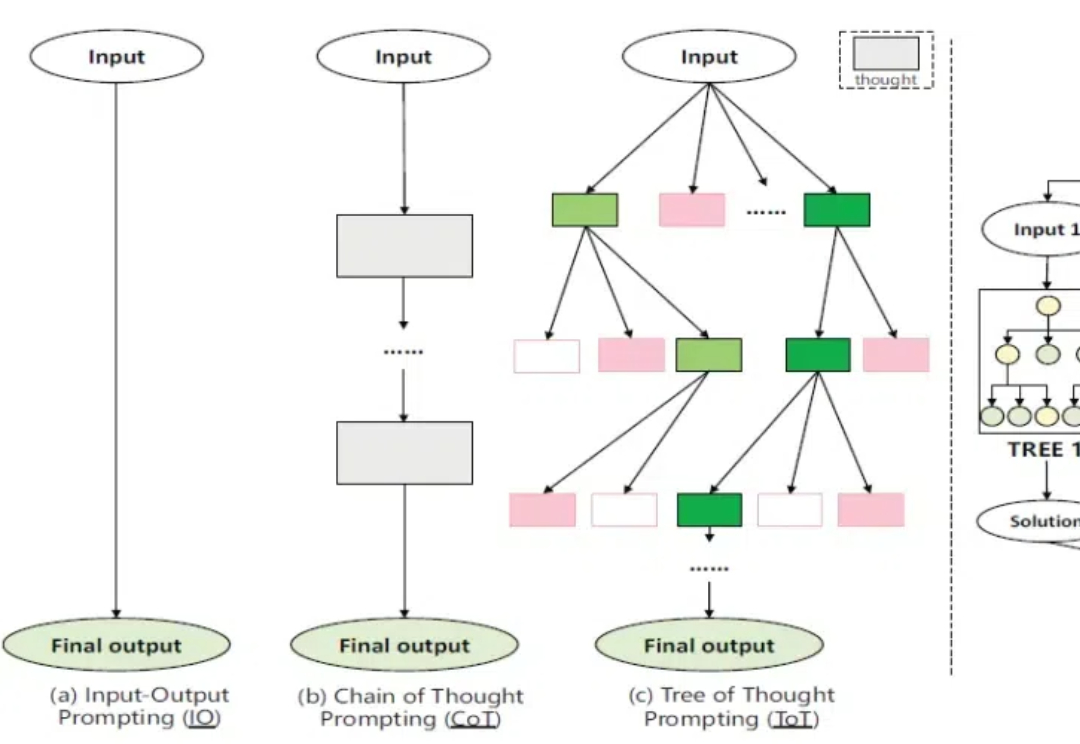
OpenAI 接连发布 o1 和 o3 模型,大模型的高阶推理能力正在迎来爆发式增强。在预训练 Scaling law “撞墙” 的背景下,探寻新的 Scaling law 成为业界关注的热点。高阶推理能力有望开启新的 Scaling law,为大模型的发展注入新的活力。